Machine Learning Techniques - 1
Mathematical foundations to Modelling and ML
Probability
- Definition: The likelihood of an event to occur
- \(\Omega\): All possible events
- Example with probability tree

- \[\sum_{\omega \in \Omega}\mathbb{P}(\omega) = 1\]
Standardized moments

The nth standardized moment \(\gamma_k = \frac{\mu_k}{(\sigma)^k}\)
\(\gamma_1 = 0\), \(\gamma_2 = 1\)
Skewness the 3rd standardized moment:
- Skewness is a measure of asymmetry around the function mean or location.
Kurtosis the 3rd standardized moment:
- (from Greek: κυρτός, kyrtos or kurtos, meaning “curved, arching”)
- Kurtosis is a measure of tailedness
Continuous Law : Normal
- Normal(Gaussian) distribution
- 2 parameters
- \(\mu\) – location or mean
- \(\sigma > 0\) – standard deviation
| Moment | Value |
|---|---|
| \(E(X)\) | \(\mu\) |
| \(\text{Var}(X)\) | \(\sigma^2\) |
| Skewness | 0 |
| Kurtosis | 3 |

\(f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\)
Continuous Law : Gamma
- Gamma distribution (Real Positive)
- 2 parameters
- \(\alpha > 0\) – shape
- \(\lambda > 0\) – rate
| Moment | Value |
|---|---|
| \(E(X)\) | \(\frac{\alpha}{\lambda}\) |
| \(\text{Var}(X)\) | \(\frac{\alpha}{\lambda^2}\) |
| Skewness | \(\frac{2}{\sqrt{\alpha}}\) |
| Kurtosis | \(3 + \frac{6}{\alpha}\) |

\(f(x) = \frac{\lambda^\alpha x^{\alpha-1}}{\Gamma(\alpha)} e^{-\lambda x}\)
Nelder-Mead Optimization3
function nelder_mead(f, s0, coef, max_it=1000, tol=1e-6):
"""
f: target function to be minimized
s0: list of n+1 initial guesses (vertices of the initial simplex)
coef: reflection, contraction, expansion, shrink coefficients
max_it: maximum number of iterations allowed
tol: stopping criterion for the difference in function values
"""
s = s0
for it in range(max_it):
s.sort(key=lambda v: f(v)) # Sorting from low to high
centroid = [sum(v[i] for v in s[:-1]) # Without the worst
refl_v = centroid + coef[0] * (centroid - s[-1]) # Reflect the worst
if f(s[0]) <= f(refl_v) < f(s[-2]): # if good but not best
simplex[-1] = refl_v # replace the worst
elif f(refl_v) < f(s[0]): # elif best, try expansion
expe_v = centroid + coef[1] * (refl_v - centroid)
if f(expe_v) < f(s[0]): simplex[-1] = expe_v
else: simplex[-1] = refl_v
else: # contract the worst or shrink all others
cont_v = centroid + coef[2] * (s[-1] - centroid)
if f(cont_v) < f(s[-1]): s[-1] = cont_v
else: s = [s[0] + coef[3] * (s[i] - s[0]) for i in range(1, len(s))]
if abs(f(s[-1]) - f(s[0])) < tol:
return s[0]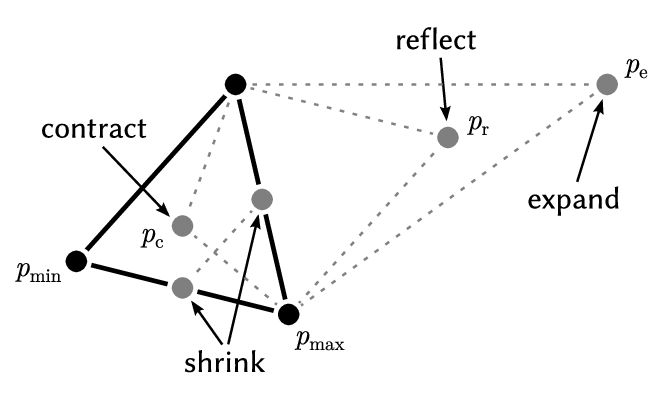
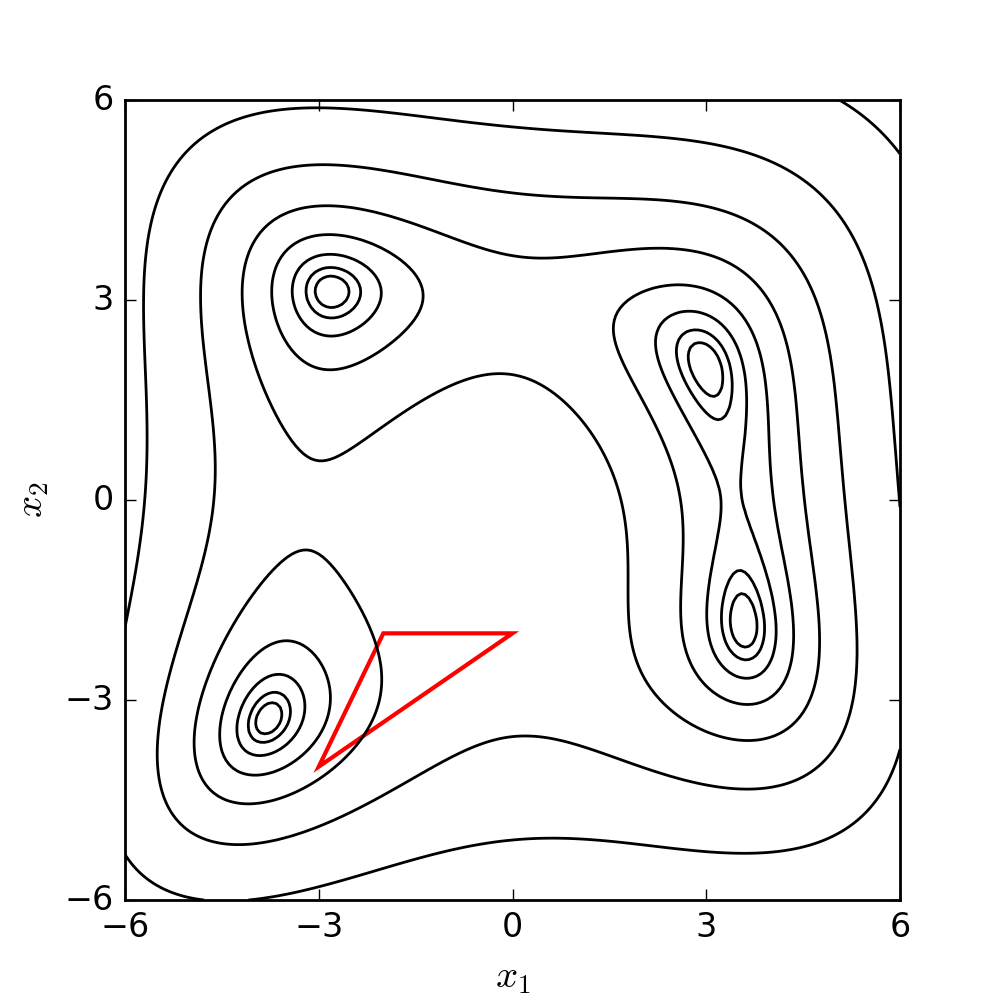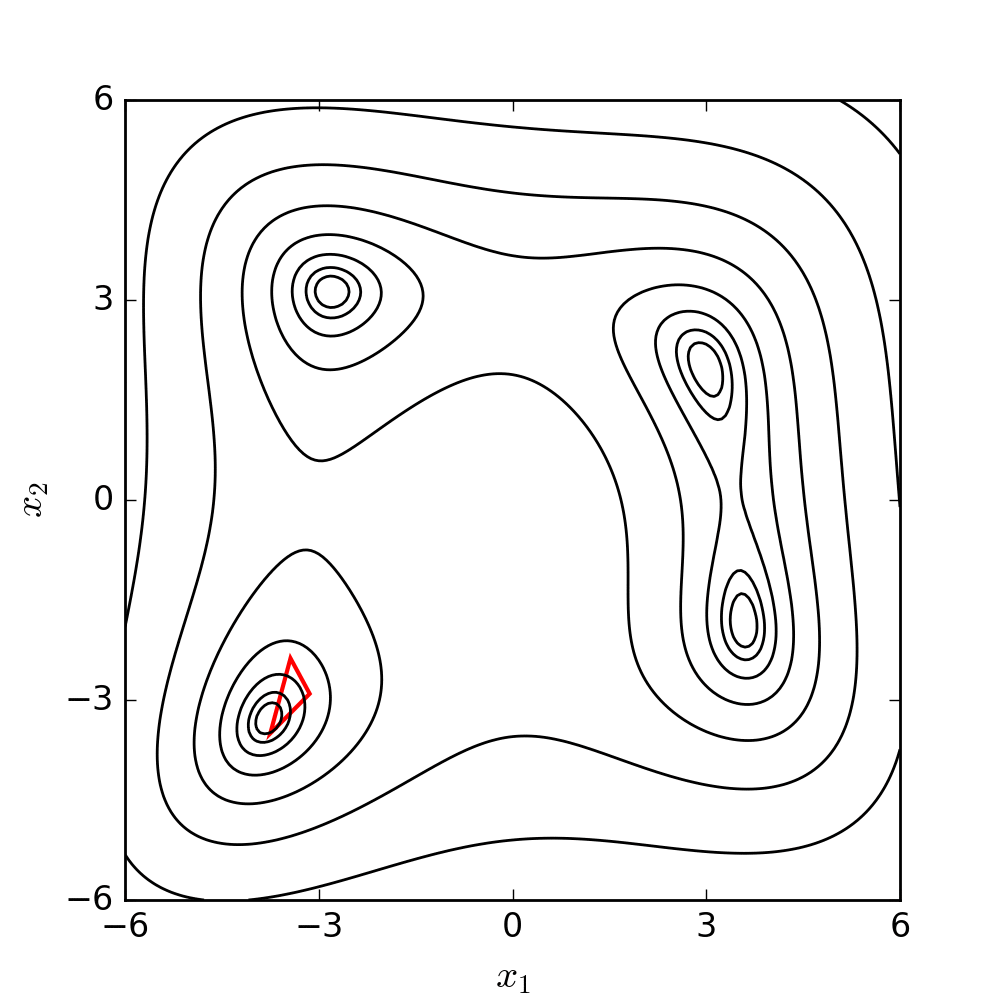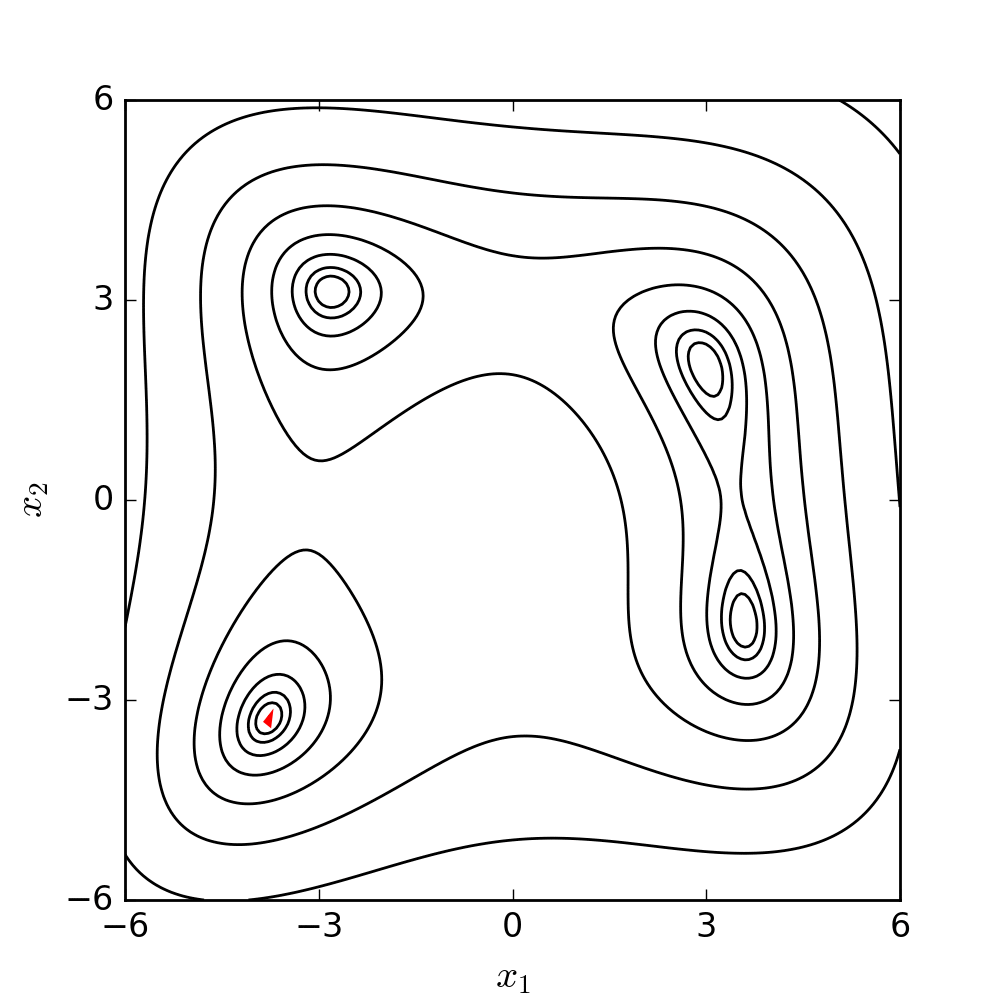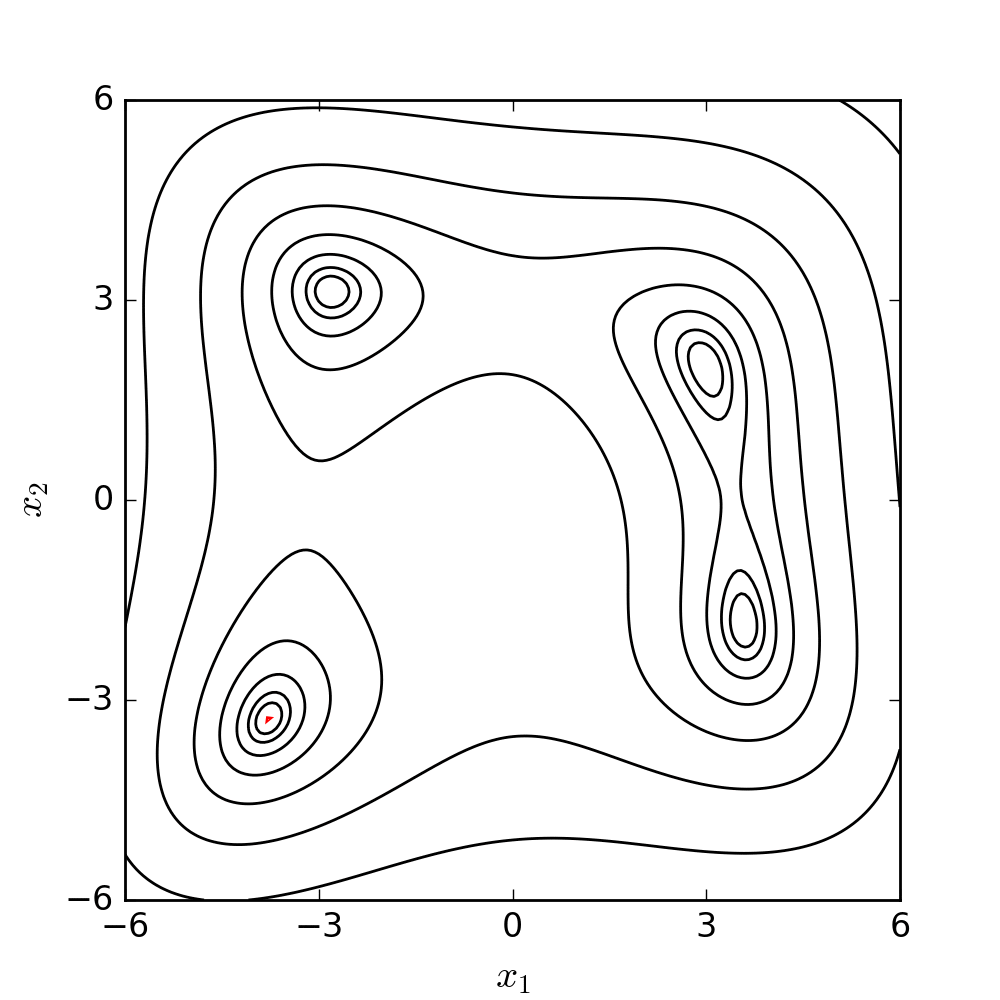
Source: WIKIPEDIA
Recommendation to go further7
Playlist on youtube
X, Data or Features
Features: Variables that are collected for each “observation”. Nature of those variables can be diverse (E.g. measure, design).
X: Often refers to the matrix of feature with lines as observations and columns as features.
Data: Data can refers to X or to a larger entity with the target value (variable to predict)

Y, Targets, Predicted Values or Transformed Values
Y typically represents the variable or the output in statistical modeling and machine learning.
Targets: The actual values of Y in the dataset. These are what the model aims to predict or reproduce.
Predicted Values (\(\hat{Y}\)): The values of Y as estimated or predicted by the model based on the features, X.
Transformed Values: The values of Y as estimated or predicted by the model based on the features, X when there is no meaning for prediction as there are no target value (unsupervised)

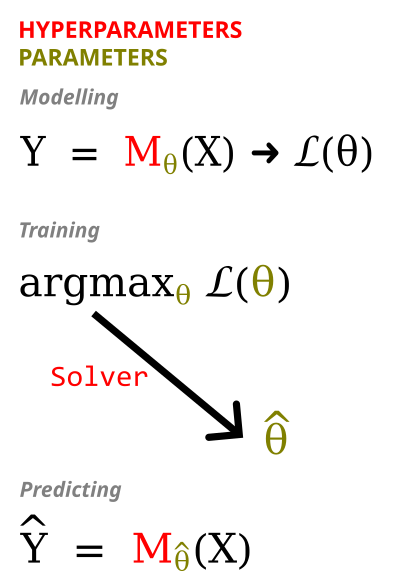
M/F, Model, Parameters and Hyperparameters
M or F stands for the model or function that is being trained or used for predictions/transformations.
Model: Represents the specific algorithm or method being used to learn from data and make predictions. Examples include linear regression, decision tree, neural network, etc.
Parameters: Part of the model that is being trained from the data through optimization to maximize the objective function.
Hyperparameters: Part of the model that is set before the optimization of parameters. Nevertheless, hyperparameters can be learned thanks to nested optimizations using validation techniques.