Machine Learning Techniques - 2
ML techniques and Good practices
In-sample and Out-sample
In-sample error: Calculated from data used for training.
Out-sample error: Calculated from unseen data (not used in training)
2 sampling with n = 10
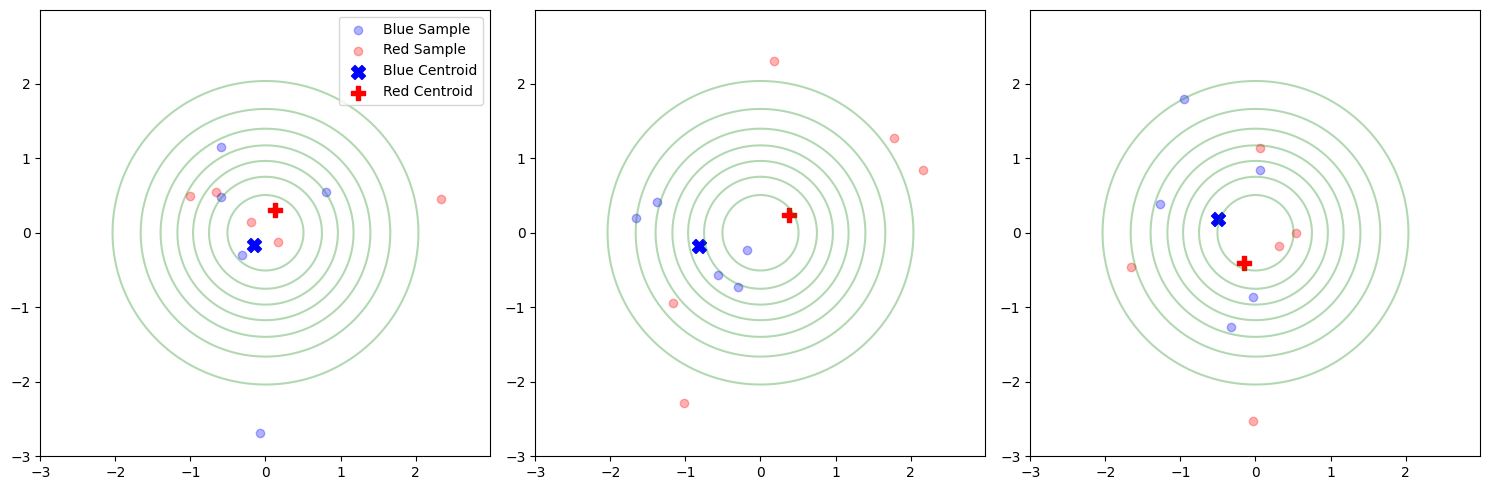
In-sample and Out-sample
Importance of validating using unseen data.
2 sampling with n = 50
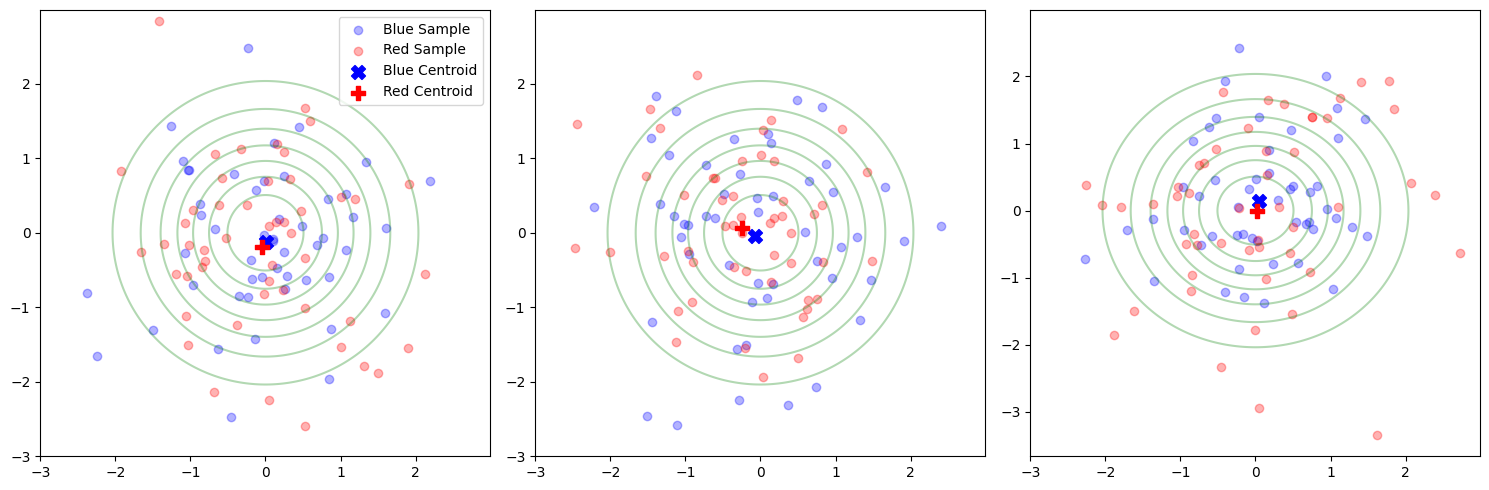
In-sample and Out-sample
Difference are lower with larger samples.
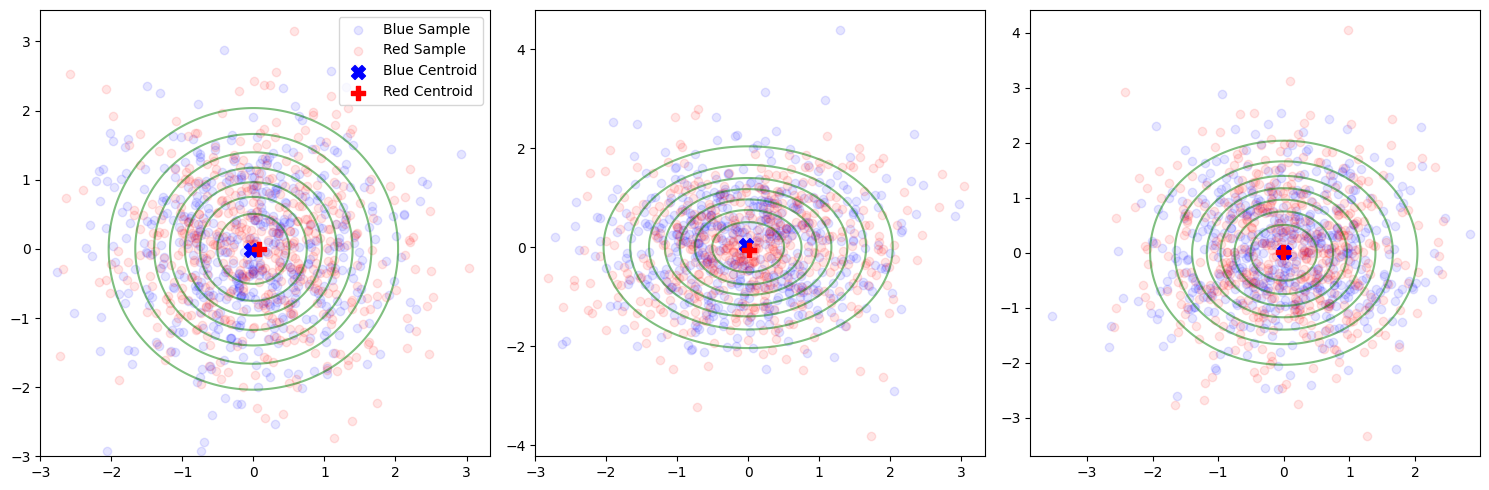
2 sampling with n = 500
Mean Squared Error Decomposition
\(\text{MSE} = \mathbb{E}[(Y - \hat{Y})^2]\)
This can be further decomposed as:
\[ \text{MSE} = \text{Bias}^2 + \text{Variance} + \text{Irreducible Error} \]
Where:
- \(\text{Bias}(\hat{Y}) = \mathbb{E}[\hat{Y}] - Y\)
- \(\text{Variance} = \mathbb{E}[(\hat{Y} - \mathbb{E}[\hat{Y}])^2]\)

Under and Overfitting
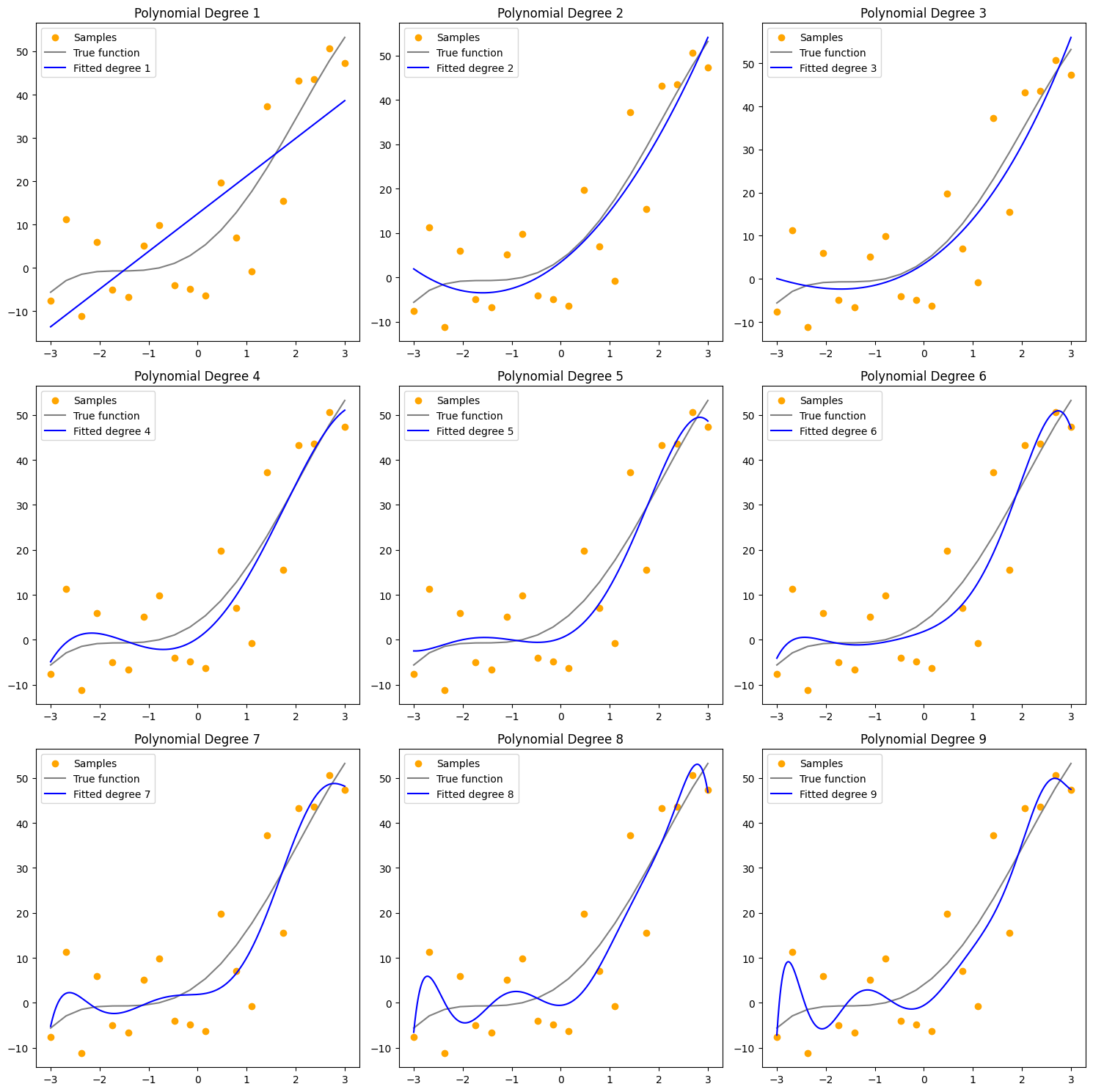
- degree 1: underfit
- ? data true pattern
- Higher Bias
- degree 8-9: overfit
- random error pattern
- Higher Variance
Under, Over and “Okay” -fitting
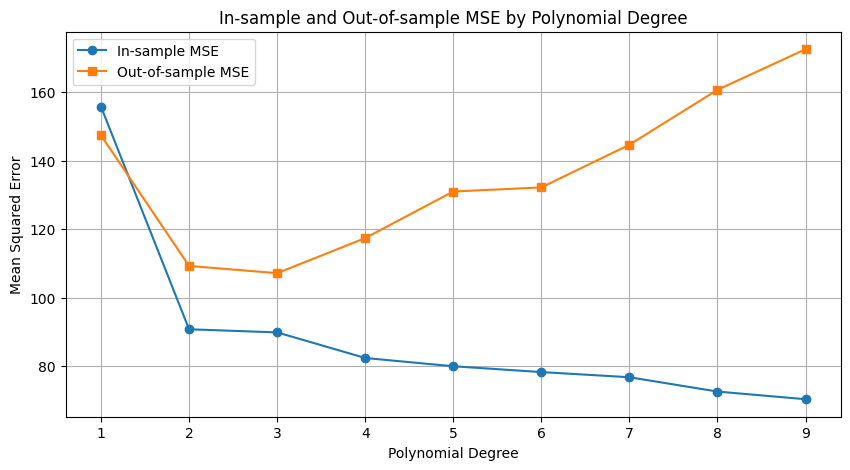
If decomposed we would see
- increased variance (out) on high degree
- increased bias (out) on low degree
- We need a “bias-variance tradeoff”
The Okay-fit is where the model:
- Learns data pattern
- Can generalize on unseen data
- Does not learn the random error pattern
WARNING: Bias variance decomposition does not always make sense.
Mandatory ML workflow

Training data → in-sample error
Test data → out-sample error
Test data should be without bias
No bias = the same error model
Not required but recommended: adversarial datasets
Importance of bias in datasets

What is the pattern of wrong prediction ?
Importance of Explainable AI
Testing is good but explaining is better:

ML workflow with model selection
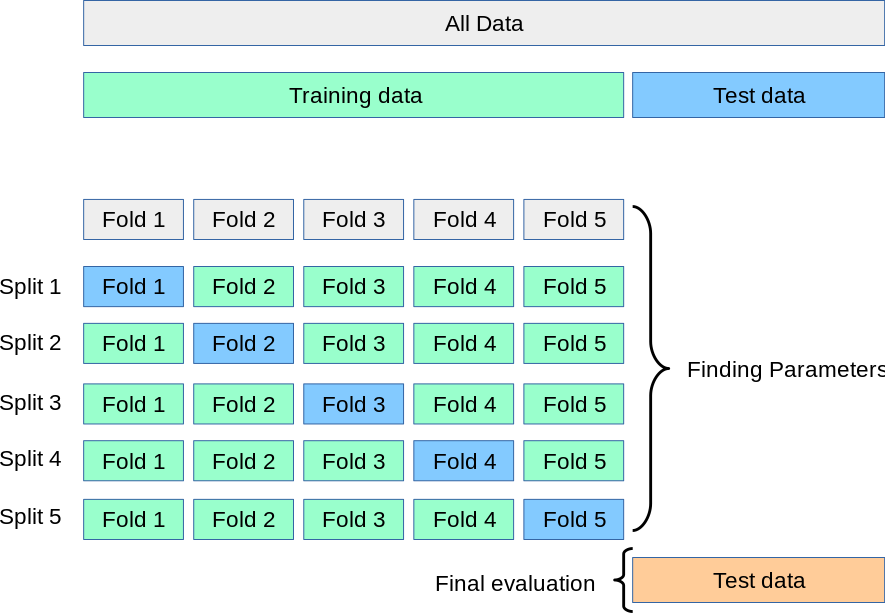
VALIDATION IS NOT TESTING

- Model selection
- Hyperparameter tuning
- Training parameters
- Introduction of validation data
- Training split
- Re-training the selected model
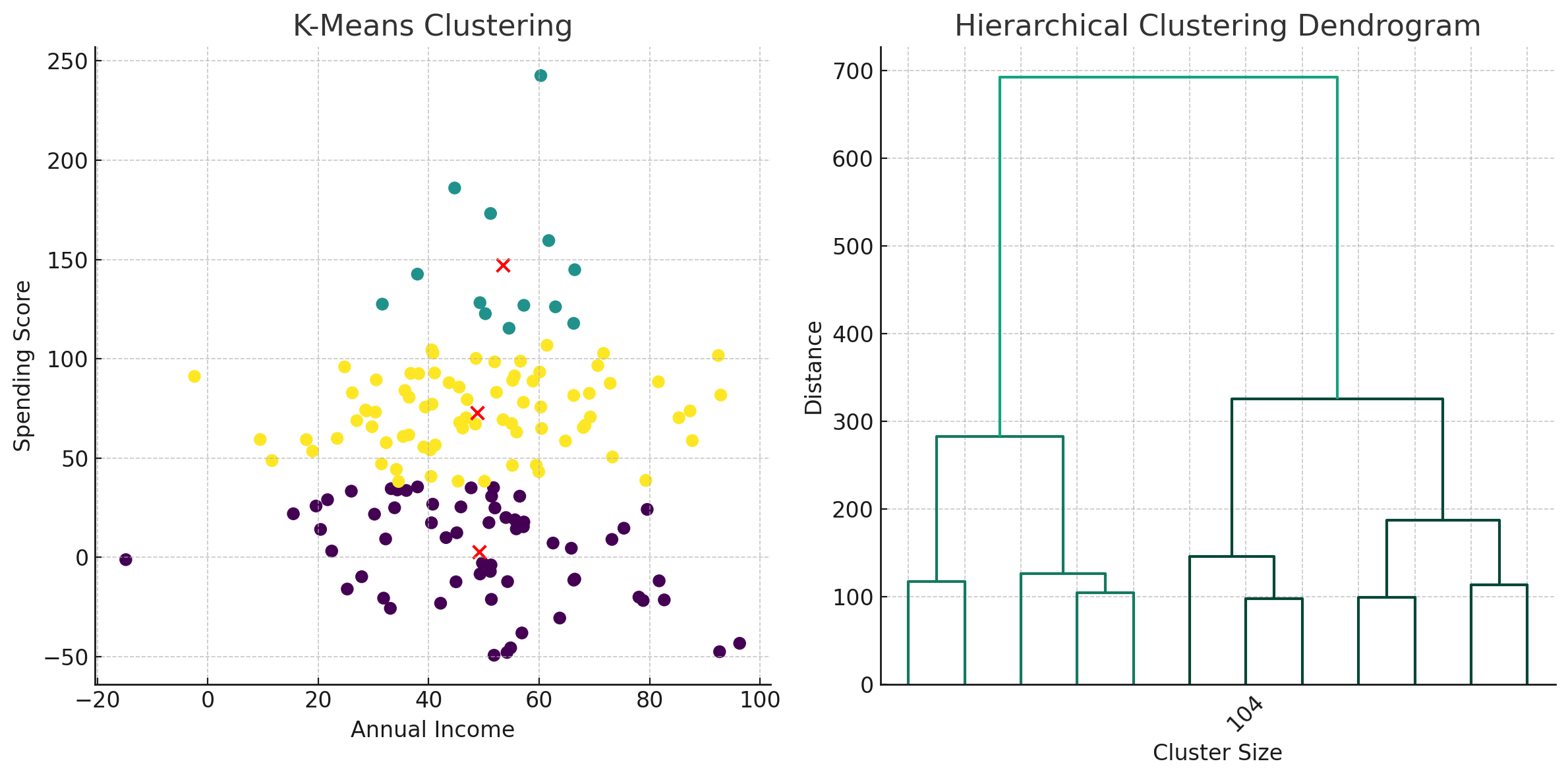
Clustering examples
- means: find groups that minimize the within-cluster sum of squares (distance to the centroid)
- Clustering
- Compute and distance matrix (Euclidean)
- Apply an agglomerative clustering (neighbor joining)
Evaluation / Binary Classification

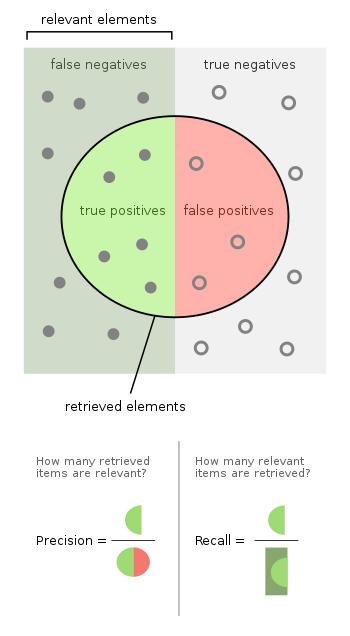
source: wikipédia
Dimentionality Reduction
Curse of dimensionality: more features = more parameters
- PCA: Principal component analysis
- Principal components (PCs) are linear expressions of features
- PCs fitted so that sample variance is maximal on the first components
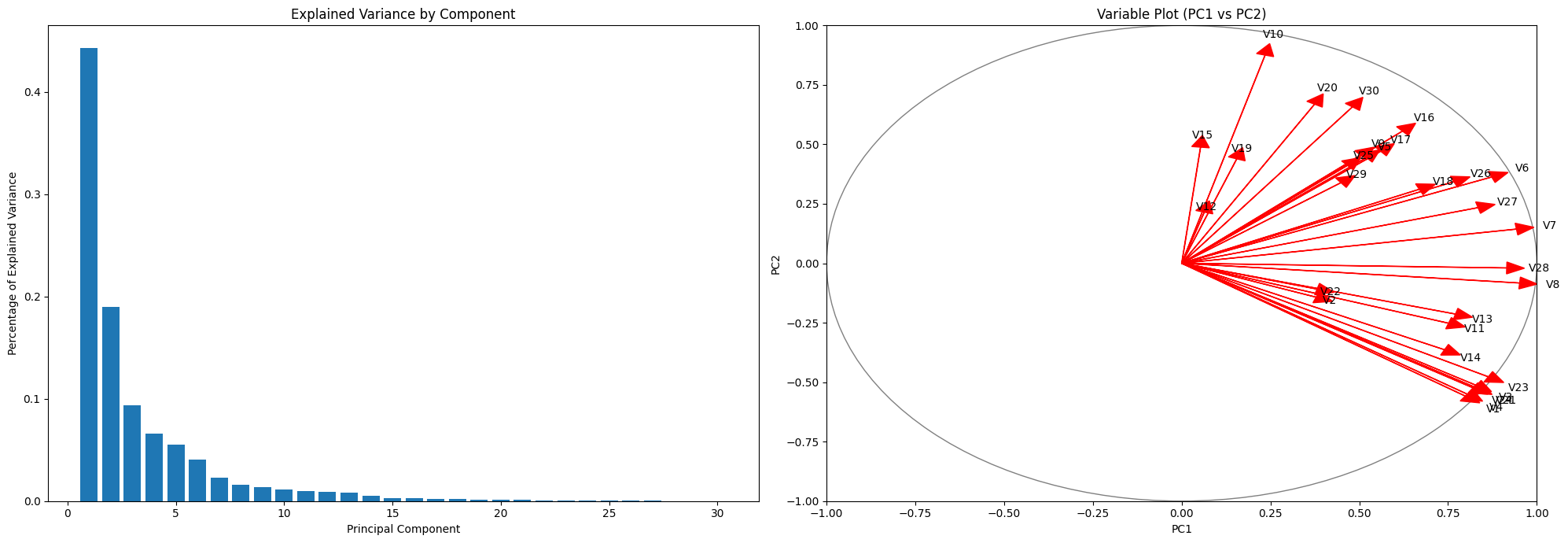
Dimensionality reduction
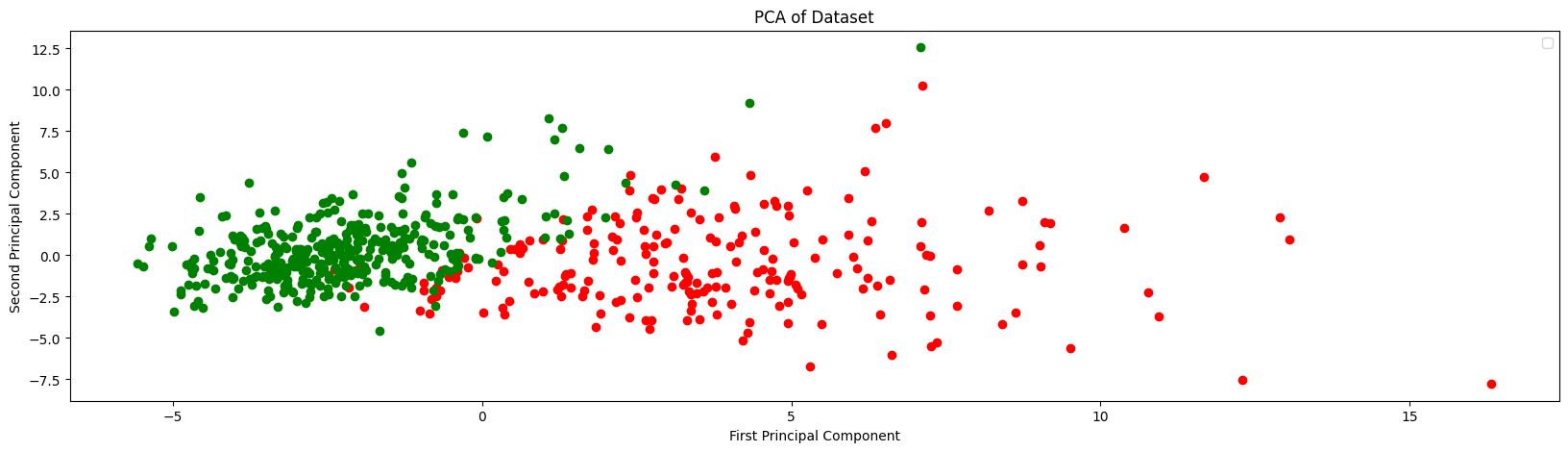
2 is nearly enough…
- Here samples are
- Target not used in PCA
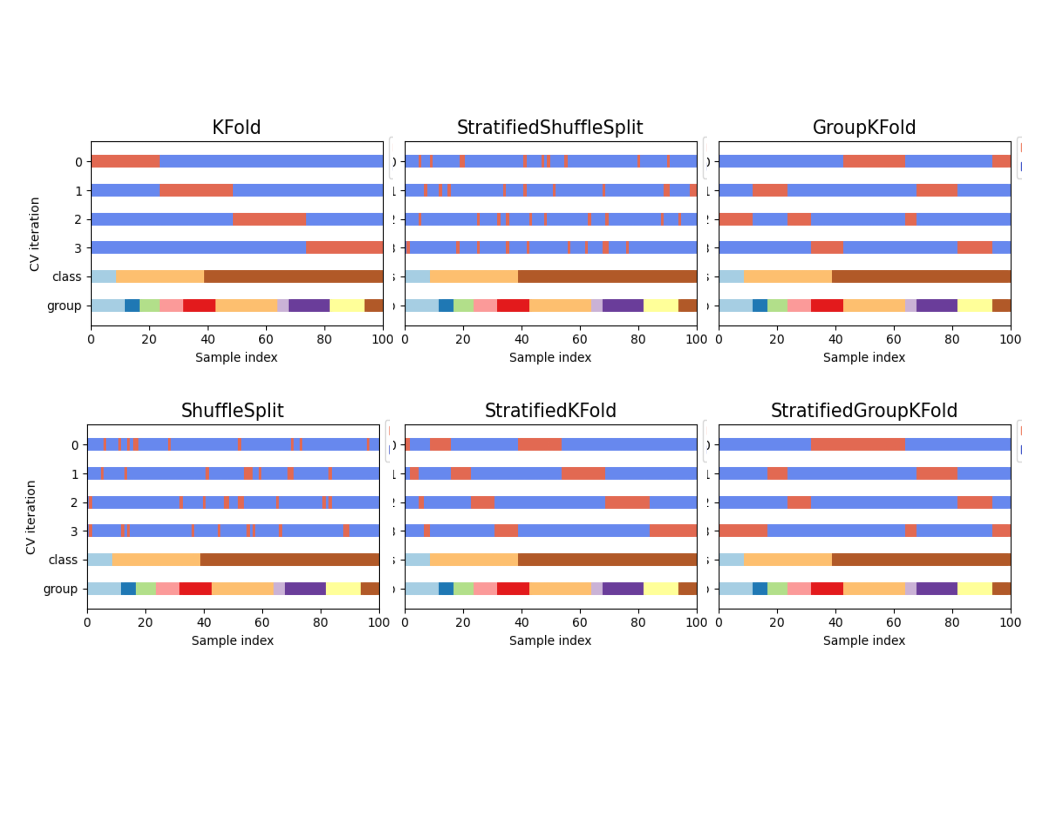
k-Fold cross-validation
Class and group in cross-validation
- Class: target
- Group: feature